If you want to run on two independent skype instances one a single machine, for example one for your personal skype account, and one for your work account, it's very simple.
Create a shortcut to your skype.exe.
Right-click it, select "Shortcut" tab.
Add /secondary to the Target field, if you have installed Skype on the default location, then this would look something like:
"C:\Program Files (x86)\Skype\Phone\Skype.exe" /secondary
Click OK to save changes and your are done.
Enjoy your alternative second skype.
Thursday, 7 November 2013
Wednesday, 6 November 2013
ERROR 267 (0x0000010B) Scanning Source Directory DIRNAME The directory name is invalid. Jenkins
A job that I run on my Jenkins CI suddenly started having this error:
ERROR 267 (0x0000010B) Scanning Source Directory DIRECTORY-PATH The directory name is invalid.
The job was using a robocopy command to find and copy all config.xml files from the JENKINS_HOME/jobs and commit them to the SVN repository for backup.
This job which was causing the issue was a matrix type of job, that was previously running on multiple slave nodes and later was changed to run to a different node, so there were left old folders in the directory:
JENKINS_HOME\jobs\JOBNAME\configurations\axis-label\NODENAME\...
So now I had these folders in that location:
\Old_NODENAME
\Current_NODENAME
What I did was to delete the \Old_NODENAME, as it obviously was not done automatically by Jenkins once I had changed the matrix configuration (the nodes I want the job to run simultaneously)
Then I run the job again, to just make sure it was passing successfully.
I also manually deleted the info about the Old_NODENAME which was stored at the SVN.
After performing these two steps, I run the failing job again, and the error 267 was fixed.
Old and irrelevant content in the job's workspace on JENKINS_HOME/jobs and on the SVN where the job commits, were causing ERROR 267 (0x0000010B) Scanning Source Directory DIRECTORY-PATH The directory name is invalid.
OR
Another reason this error to happen was that the invalid name contained "lastSuccessful". That particular job did not have a link "Last successful artifacts" which usually is present on all jobs and is a link to the last successful build artifacts of that job. In one case such a link was missing for whatever reason, and I had to recreate the job and run it in order to make this link appear in the UI of the job in Jenkins.
ERROR 267 (0x0000010B) Scanning Source Directory DIRECTORY-PATH The directory name is invalid.
The job was using a robocopy command to find and copy all config.xml files from the JENKINS_HOME/jobs and commit them to the SVN repository for backup.
This job which was causing the issue was a matrix type of job, that was previously running on multiple slave nodes and later was changed to run to a different node, so there were left old folders in the directory:
JENKINS_HOME\jobs\JOBNAME\configurations\axis-label\NODENAME\...
So now I had these folders in that location:
\Old_NODENAME
\Current_NODENAME
What I did was to delete the \Old_NODENAME, as it obviously was not done automatically by Jenkins once I had changed the matrix configuration (the nodes I want the job to run simultaneously)
Then I run the job again, to just make sure it was passing successfully.
I also manually deleted the info about the Old_NODENAME which was stored at the SVN.
After performing these two steps, I run the failing job again, and the error 267 was fixed.
Old and irrelevant content in the job's workspace on JENKINS_HOME/jobs and on the SVN where the job commits, were causing ERROR 267 (0x0000010B) Scanning Source Directory DIRECTORY-PATH The directory name is invalid.
OR
Another reason this error to happen was that the invalid name contained "lastSuccessful". That particular job did not have a link "Last successful artifacts" which usually is present on all jobs and is a link to the last successful build artifacts of that job. In one case such a link was missing for whatever reason, and I had to recreate the job and run it in order to make this link appear in the UI of the job in Jenkins.
Friday, 16 August 2013
Error 0x8007046A:Not enough server storage is available to process this command.
I was trying to move a 10 GB folder on another network location but this error prevents me from doing it:
Error 0x8007046A:Not enough server storage is available to process this command.
1. Click Start | Run and type regedit.
2. Locate the registry key HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\LanmanServer\Parameters
3. Click Edit and Add Value with the following parameters
Name: MinFreeConnections
Data Type: Reg_DWORD
Decimal: 5
This fixed my problem.
Error 0x8007046A:Not enough server storage is available to process this command.
1. Click Start | Run and type regedit.
2. Locate the registry key HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\LanmanServer\Parameters
3. Click Edit and Add Value with the following parameters
Name: MinFreeConnections
Data Type: Reg_DWORD
Decimal: 5
This fixed my problem.
Tuesday, 26 March 2013
Directory-based selection in ANT
To match a pattern of path to resources, use *:
* matches only the first sub-directory and its content, plus the files of the current dir, no other directories
** matches all sub-directoryes and their content
for example, c:\path\to\something\** will match everything under \something
to include the current dir for file search, start pattern path with **
Matching is done per-directory. This means that first the first directory in the pattern is matched against the first directory in the path to match. Then the second directory is matched, and so on. For example, when we have the pattern
To make things a bit more flexible, we add one extra feature, which makes it possible to match multiple directory levels. This can be used to match a complete directory tree, or a file anywhere in the directory tree. To do this,
There is one "shorthand": if a pattern ends with
Example patterns:
* matches only the first sub-directory and its content, plus the files of the current dir, no other directories
** matches all sub-directoryes and their content
for example, c:\path\to\something\** will match everything under \something
to include the current dir for file search, start pattern path with **
Matching is done per-directory. This means that first the first directory in the pattern is matched against the first directory in the path to match. Then the second directory is matched, and so on. For example, when we have the pattern
/?abc/*/*.java
and the path /xabc/foobar/test.java,
the first ?abc is matched with xabc,
then * is matched with foobar,
and finally *.java is matched with test.java.
They all match, so the path matches the pattern.To make things a bit more flexible, we add one extra feature, which makes it possible to match multiple directory levels. This can be used to match a complete directory tree, or a file anywhere in the directory tree. To do this,
**
must be used as the name of a directory.
When ** is used as the name of a
directory in the pattern, it matches zero or more directories.
For example:
/test/** matches all files/directories under /test/,
such as /test/x.java,
or /test/foo/bar/xyz.html, but not /xyz.xml.There is one "shorthand": if a pattern ends with
/
or \, then **
is appended.
For example, mypackage/test/ is interpreted as if it were
mypackage/test/**.Example patterns:
**/CVS/* |
Matches all files in CVS
directories that can be located
anywhere in the directory tree.Matches: CVS/Repository
org/apache/CVS/Entries
org/apache/jakarta/tools/ant/CVS/Entries
But not:
org/apache/CVS/foo/bar/Entries (
|
org/apache/jakarta/** |
Matches all files in the org/apache/jakarta
directory tree.Matches: org/apache/jakarta/tools/ant/docs/index.html
org/apache/jakarta/test.xml
But not:
org/apache/xyz.java
(jakarta/ part is missing). |
org/apache/**/CVS/* |
Matches all files in CVS directories
that are located anywhere in the directory tree under
org/apache.Matches: org/apache/CVS/Entries
org/apache/jakarta/tools/ant/CVS/Entries
But not:
org/apache/CVS/foo/bar/Entries
(foo/bar/ part does not match) |
**/test/** |
Matches all files that have a test
element in their path, including test as a filename. |
Run command prompt on remote Win machine
Install Sysinternals Process Utilities from:
psexec \\marklap cmd
This command executes IpConfig on the remote system with the /all switch, and displays the resulting output locally:
psexec \\marklap ipconfig /all
This command copies the program test.exe to the remote system and executes it interactively:
psexec \\marklap -c test.exe
Specify the full path to a program that is already installed on a remote system if its not on the system's path:
psexec \\marklap c:\bin\test.exe
http://technet.microsoft.com/en-us/sysinternals/bb795533
PsExec Execute processes remotely.
The following command launches an interactive command prompt on \\marklap:psexec \\marklap cmd
This command executes IpConfig on the remote system with the /all switch, and displays the resulting output locally:
psexec \\marklap ipconfig /all
This command copies the program test.exe to the remote system and executes it interactively:
psexec \\marklap -c test.exe
Specify the full path to a program that is already installed on a remote system if its not on the system's path:
psexec \\marklap c:\bin\test.exe
Process Explorer Find out which process locks a resource (Find menu), what files, registry keys and other objects processes have open, which DLLs they have loaded
Wednesday, 20 March 2013
Linux processes
To find a process
Use pgrep command. pgrep looks through the currently running processes and lists the process IDs which matches the selection criteria to screen. For example display firefox process id:# pgrep firefoxSample outputs:
3356
or
# pidof firefox3356 Following command will list the process called sshd which is owned by a user called root:
$ pgrep -u root sshd# ps 3356Sample outputs:
PID TTY STAT TIME COMMAND
3356 ? .. .. /path/to/executable
pstree shows running processes as a tree. If a user name is specified, all process trees rooted at processes owned by that user are shown.
$ pstreeps -u user will show all processes of the user "user"
$ ps -u user
Thursday, 14 March 2013
VNC server on Linux
Setup VNC server on a Linux machine
Login with the user for which you want to allow remote desktop and enable vncserver startup from System ->Administration->Server Settings->Service configuration
Add the following lines to /etc/sysconfig/vncservers
VNCSERVERS="1:#username#”
VNCSERVERARGS[1]="-geometry 1024x768 -depth 16"
where #username# is the name of the user for which you want to allow remote desktop.
Start and stop VNC server to create the VNC startup file /home/ciuser/.vnc/xstartup
vncserver :1
vncserver -kill :1
The of /home/#username#/.vnc/xstartup must be as follows
#!/bin/sh
vncconfig -iconic &
# Uncomment the following two lines for normal desktop:
unset SESSION_MANAGER
exec /etc/X11/xinit/xinitrc
[ -x /etc/vnc/xstartup ] && exec /etc/vnc/xstartup
[ -r $HOME/.Xresources ] && xrdb $HOME/.Xresources
xsetroot -solid grey
xterm -geometry 80x24+10+10 -ls -title "$VNCDESKTOP Desktop" &
Copy & Paste the lines above into /home/#username#/.vnc/xstartup where #username# is the name of the user for which you want to allow remote desktop.
vncserver uses the ports
5901 for display
:1,
5902 for display
:2, and so on. The sessions are available on ports
5901 for
“regular” VNC viewers (equivalent to VNC display
1) and on port
5801 for Web browsers.
For example, in the browser you can access a machine with VNC server running:
http://machineName:5801
which is equal to using a VNC desktop client, on this one you will use
machineName:5901
Wednesday, 13 March 2013
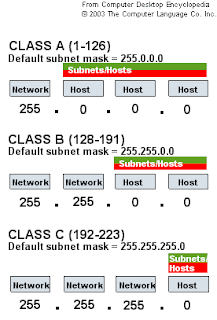
IP classes A, B, C, D, E
IP addresse are of different classes:
Class A (1-127):
first octet always starts with 0 and is for the network address and next three octets - for the unique hosts inside the network.
Class B (128-191):
first octet always starts with 10. First and second octets are for the network address and next two octets - for the unique hosts inside the network.
Class C (192-223):
first octet always starts with 110. First three octets are for the network address and the last octet - for the unique hosts inside the network.

Class A (1-127):
first octet always starts with 0 and is for the network address and next three octets - for the unique hosts inside the network.
Class B (128-191):
first octet always starts with 10. First and second octets are for the network address and next two octets - for the unique hosts inside the network.
Class C (192-223):
first octet always starts with 110. First three octets are for the network address and the last octet - for the unique hosts inside the network.


DHCP and DNS
DHCP - responds to requests from clients giving them unique IP address, subnet, gateaway, DNS server which are valide for a pecified period of time (TTL).
Having DHCP server to automatically configure machines in the network takes off the responsibilite of admins to configure each machine.
DNS - returns to client (like browser) the IP that corresponds to a given domain name.
Having DHCP server to automatically configure machines in the network takes off the responsibilite of admins to configure each machine.
DNS - returns to client (like browser) the IP that corresponds to a given domain name.
Thursday, 7 March 2013
Move/copy virtual machine around VMware environment
Goal is to move/copy a virtual machine to another datastore on another VMware server for virtualization, like ESXi.
In other words, create and register in the vSphere (VMware Workstation) a new VM from existing uploaded folder with such machine.
1. Physically move the directory of the virtual machine:
a) via Browse datastore to download it on the local machine and the via the Browse datastore on the other server upload it there
b) use VMware vCenter Converter http://www.vmware.com/products/converter/overview.html , this tool will relocate any machine around, just fill in appropriate IP of the source and destination servers
2. Once the virtual machine folder is uploaded, right-click the .vmx file -> Add to inventory.
This will add the machine to the list of machines in the left pane of the vSphere or VMware Workstation
You still may experience network conflicts of IP, MAC and so on after copying/moving a VM to new datastore, because it brings along the old network data (IP, MAC and so on). So you need to get new network data for the new machine.
FORCE VMWare To Generate a New MAC Address
The most common scenario for wanting to do this is if you’ve used a “template” Guest OS and copied it to multiple PCs, but accidentally clicked “I moved this Virtual Machine” rather than “I copied this Virtual Machine” when first booting the Guest OS in something like VMware Player.
If you tell VMware that the Guest OS was copied, it automatically generates new UUID info and MAC addresses. If you tell VMware that you moved the Guest OS, all unique identifiers are left alone (including the MAC address). By performing the steps above, you can get VMware to generate you some new, unique identifiers, and stop weirdness on your network
In other words, create and register in the vSphere (VMware Workstation) a new VM from existing uploaded folder with such machine.
1. Physically move the directory of the virtual machine:
a) via Browse datastore to download it on the local machine and the via the Browse datastore on the other server upload it there
b) use VMware vCenter Converter http://www.vmware.com/products/converter/overview.html , this tool will relocate any machine around, just fill in appropriate IP of the source and destination servers
2. Once the virtual machine folder is uploaded, right-click the .vmx file -> Add to inventory.
This will add the machine to the list of machines in the left pane of the vSphere or VMware Workstation
You still may experience network conflicts of IP, MAC and so on after copying/moving a VM to new datastore, because it brings along the old network data (IP, MAC and so on). So you need to get new network data for the new machine.
FORCE VMWare To Generate a New MAC Address
- Shut down the Guest OS.
- Open up the .vmx file.
- Delete the following lines (that begin with…):
ethernet0.addressType uuid.location = uuid.bios = ethernet0.generatedAddress = ethernet0.generatedAddressOffset =
- Boot up the Guest OS again, and it should generate new details in the vmx file (I’d check afterwards to be doubly sure).
The most common scenario for wanting to do this is if you’ve used a “template” Guest OS and copied it to multiple PCs, but accidentally clicked “I moved this Virtual Machine” rather than “I copied this Virtual Machine” when first booting the Guest OS in something like VMware Player.
If you tell VMware that the Guest OS was copied, it automatically generates new UUID info and MAC addresses. If you tell VMware that you moved the Guest OS, all unique identifiers are left alone (including the MAC address). By performing the steps above, you can get VMware to generate you some new, unique identifiers, and stop weirdness on your network
Thursday, 21 February 2013
Find files
$ find /dir/to/search -name "fileName"
$ find -name "fileName*"
this will search in the current directory and its sub-directories . It turned out that on my RedHat I had to use " " instead of single quotes ' '
$ find /dir/to/search -type d -name "dirName"
search for a directory with name "dirName"
$ find -name "fileName*"
this will search in the current directory and its sub-directories . It turned out that on my RedHat I had to use " " instead of single quotes ' '
$ find /dir/to/search -type d -name "dirName"
search for a directory with name "dirName"
Wednesday, 20 February 2013
Symbolik links (soft link)
$ ln -s /path/to/link/to /place/symlink/here
$ ln -s /home/user/ MySymlink
will create symbolik link "MySymlink" that will link to the path /home/user
$ ln -s /home/user/ MySymlink
will create symbolik link "MySymlink" that will link to the path /home/user
#!/bin/sh and its options -x and -e
Let’s look at an example.
It will be zero, always. Why?
Because the exit code of a script is the exit code of the last command and the echo command will succeed with very high probability.
The shell has a convenient option -e, which causes shell to stop running a script immediately when any command exits with non-zero exit code. This makes it easy to have Jenkins know when your script fails.
By the way, there’s also one more useful shell option you might want to know about, -x, which makes shell print every command it executes.
#!/bin/sh -xe will exit if any command exits with non-zero exit code AND will print every command that is executed
#!/bin/shWhat is the exit code of the script above?
make
echo “Build exit code was $?”
It will be zero, always. Why?
Because the exit code of a script is the exit code of the last command and the echo command will succeed with very high probability.
The shell has a convenient option -e, which causes shell to stop running a script immediately when any command exits with non-zero exit code. This makes it easy to have Jenkins know when your script fails.
By the way, there’s also one more useful shell option you might want to know about, -x, which makes shell print every command it executes.
#!/bin/sh -xe will exit if any command exits with non-zero exit code AND will print every command that is executed
Tuesday, 19 February 2013
Get information about Linux partitions
To Display Hard Disk Partition Size in Mega bytes or GB or TB: $ df -HTo list all block devices, run:
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 1 558G 0 disk ├─sda1 8:1 1 307M 0 part /boot ├─sda2 8:2 1 250G 0 part /webroot ├─sda3 8:3 1 6G 0 part [SWAP] ├─sda4 8:4 1 1K 0 part └─sda5 8:5 1 301.7G 0 part / sr0 11:0 1 1024M 0 rom
To determine the file system type or to find out what type of file systems currently mounted:$ df -T df command report filesystem disk space usage and if you pass -T option it will report filesystem type.
$ mount /dev/hdb1 on / type ext3 (rw,errors=remount-ro) /dev/hdb2 on /home type ext3 (rw,errors=remount-ro) proc on /proc type proc (rw) sysfs on /sys type sysfs (rw) devpts on /dev/pts type devpts (rw,gid=5,mode=620) tmpfs on /dev/shm type tmpfs (rw) usbfs on /proc/bus/usb type usbfs (rw) automount(pid3558) on /data type autofs (rw,fd=4,pgrp=3558,minproto=2,maxproto=4)
As you can see, second last column displays the file system type. For example first line [/dev/hdb1 on / type ext3 (rw,errors=remount-ro)] can be interpreted as follows:
- /dev/hdb1 : Partition
- / : File system
- ext3 : File system type
- (rw,errors=remount-ro) : Mount options
fdisk -l
Disk /dev/sda: 251.1 GB, 251059544064 bytes
255 heads, 63 sectors/track, 30522 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x0008fcd3
Device Boot Start End Blocks Id System
/dev/sda1 * 1 14 104448 83 Linux
Partition 1 does not end on cylinder boundary.
/dev/sda2 14 13068 104857600 83 Linux
/dev/sda3 13068 13198 1048576 82 Linux swap / Solaris
/dev/sda4 13198 30523 139163648 5 Extended
/dev/sda5 13198 30523 139162624 83 Linux
the star on /dev/sda1 shows that this is the bootable partitionfdisk -l | grep Disk
fdisk device {fdisk /dev/sda1}
cfdisk
- DOS-based utility to manupulate partitions
sfdisk -l /dev/sda
Syncronize system time on RedHat linux
Verify Network Time Protocol is installed and working:
$ pgrep ntpd
To sync with the time server:
as ROOT
$ /etc/init.d/ntpd stop
$ /etc/init.d/ntpd start
OR
$ /etc/init.d/ntpd restart
System - Date and Time - Network time should contain your time server.
Monday, 18 February 2013
Download file to a specific location using WGET
WGET is unix command used to download file.
To download a file on specific location:
wget -P "C:\Users\me\Desktop" http://address/of/file.doc
To download a file on specific location:
wget -P "C:\Users\me\Desktop" http://address/of/file.doc
-P prefix
--directory-prefix=prefix
Set directory prefix to prefix. The directory prefix is the
directory where all other files and sub-directories will be
saved to, i.e. the top of the retrieval tree. The default
is . (the current directory).Friday, 15 February 2013
How to run minimized batch file as a scheduled task
In Windows, Task scheduler, Properties of the task, Actions tab, edit the task by adding:
%comspec% /c start /min
in front of the path to the script, in the field "Program/Script" where you would browse to the script on your system, for example
%comspec% /c start /min "C:\path\to\my\batchfile.bat"
%comspec% is an environment variable that points to the location of the cmd.exe on your system.
Clicking OK will invoke dialog to ask if you if you ment all this to be parameters or not. Answer NO and the task will be saved as you would expect.
Then, add
exit
at the end of the batch file that you want to run with minimized with Task scheduler.
That's all.
%comspec% /c start /min
in front of the path to the script, in the field "Program/Script" where you would browse to the script on your system, for example
%comspec% /c start /min "C:\path\to\my\batchfile.bat"
%comspec% is an environment variable that points to the location of the cmd.exe on your system.
Clicking OK will invoke dialog to ask if you if you ment all this to be parameters or not. Answer NO and the task will be saved as you would expect.
Then, add
exit
at the end of the batch file that you want to run with minimized with Task scheduler.
That's all.
Friday, 25 January 2013
How to find out which process locks a resource on Windows
If you need to delete a resource but it is locked by a process and you don't know which process it is, then use
http://technet.microsoft.com/en-us/sysinternals/bb896653.aspx
Process explorer tool , and use the Find menu , entering the name of the locked resource (file, directory)
http://technet.microsoft.com/en-us/sysinternals/bb896653.aspx
Process explorer tool , and use the Find menu , entering the name of the locked resource (file, directory)
Subscribe to:
Comments (Atom)